Last Update: March 6, 2020
Algorithm learning consists of algorithm training within training data subset for optimal parameters estimation and algorithm testing within testing data subset using previously optimized parameters. This corresponds to a supervised regression machine learning task.
This topic is part of Machine Trading Analysis with Python course. Feel free to take a look at Course Curriculum.
This tutorial has an educational and informational purpose and doesn’t constitute any type of trading or investment advice. All content, including code and data, is presented for personal educational use exclusively and with no guarantee of exactness of completeness. Past performance doesn’t guarantee future results. Please read full Disclaimer.
An example of supervised boundary-based machine learning algorithm is support vector machine [1] which consists of predicting output target feature by separating output target and input predictor features data into optimal hyper-planes. Output target prediction error regularization and time series cross-validation are used for lowering variance error source generated by a greater model complexity.
1. Kernel function.
Kernel function consists of transforming output target and input predictors feature data into higher dimensional feature space to perform linear separation into optimal hyper-planes. For supervised machine learning, linear, polynomial, Gaussian radial basis or hyperbolic tangent sigmoid functions are used.
1.1. Kernel function formula notation.
Where = linear kernel function,
= input predictor features data,
= output target feature data.
2. Algorithm definition.
Quadratic programming consists of finding optimal width coefficients by maximizing separation between output target and input predictors features data support vectors subject to output target prediction errors regularization and tolerance margin.
2.1. Algorithm formula notation.
Where = support vectors margin width coefficient,
= output target feature prediction error regularization coefficient,
= output target feature prediction error or distance outside of margins,
= output target feature data,
= input predictor features data
= intercept coefficient or bias,
= output target feature prediction error tolerance margin,
= number of observations.
3. Python code example.
3.1. Import Python packages [2].
import numpy as np
import pandas as pd
import sklearn.svm as ml
import matplotlib.pyplot as plt3.2. Support vector machine regression data reading, target and predictor features creation, training and testing ranges delimiting.
- Data: S&P 500® index replicating ETF (ticker symbol: SPY) daily adjusted close prices (2007-2015).
- Data daily arithmetic returns used for target feature (current day) and predictor feature (previous day).
- Target and predictor features creation, training and testing ranges delimiting not fixed and only included for educational purposes.
spy = pd.read_csv('Data//Support-Vector-Machine-Regression-Data.txt', index_col='Date', parse_dates=True)rspy = spy.pct_change(1)
rspy.columns = ['rspy']
rspy1 = rspy.shift(1)
rspy1.columns = ['rspy1']
rspyall = rspy
rspyall = rspyall.join(rspy1)
rspyall = rspyall.dropna()rspyt = rspyall['2007-01-01':'2014-01-01']
rspyf = rspyall['2014-01-01':'2016-01-01']3.3. Support vector machine regression fitting, output and chart.
- Support vector machine fitting within training range.
- Support vector machine fitting kernel function, cost regularization coefficient and epsilon tolerance margin not fixed and only included for educational purposes.
svmt = ml.SVR(kernel='linear', C=1.0, epsilon=0.1).fit(np.array(rspyt['rspy1']).reshape(-1, 1), rspyt['rspy'])
svmtfv = svmt.predict(np.array(rspyt['rspy1']).reshape(-1, 1))
svmtfv = pd.DataFrame(svmtfv).set_index(rspyt.index)In:
print('== Support Vector Machine Regression Coefficients ==')
print('')
print('SVM Regression Intercept:', np.round(svmt.intercept_, 6))
print('SVM Regression Weight:', np.round(svmt.coef_, 6))Out:
== Support Vector Machine Regression Coefficients ==
SVM Regression Intercept: [0.013479]
SVM Regression Weight: [[-0.057545]]plt.scatter(x=rspyt['rspy1'], y=rspyt['rspy'])
plt.scatter(x=rspyt['rspy1'], y=svmtfv)
plt.title('Support Vector Machine Regression Chart')
plt.ylabel('rspy')
plt.xlabel('rspy1')
plt.show()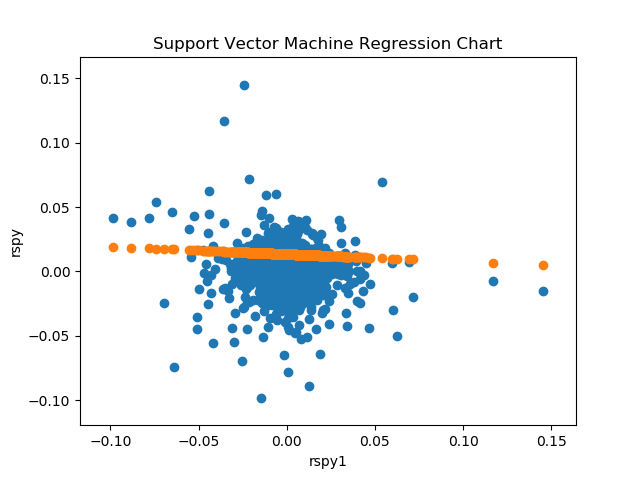
4. References.
[1] Harris Drucker, Christopher Burges, Linda Kaufman, Alexander Smola and Vladimir Vapnik. “Support Vector Regression Machines”. MIT Press. 1997.
[2] Travis E, Oliphant. “A guide to NumPy”. USA: Trelgol Publishing. 2006.
Stéfan van der Walt, S. Chris Colbert and Gaël Varoquaux. “The NumPy Array: A Structure for Efficient Numerical Computation”. Computing in Science & Engineering. 2011.
Wes McKinney. “Data Structures for Statistical Computing in Python.” Proceedings of the 9th Python in Science Conference. 2010.
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, Édouard Duchesnay. “Scikit-learn: Machine Learning in Python”. Journal of Machine Learning Research. 2011.