Last Update: February 12, 2020
Probability distributions consist of all possible values that a discrete or continuous random variable can have and their associated probability of being observed. Classical or a priori probability distribution is theoretical while empirical or a posteriori probability distribution is experimental.
This topic is part of Business Statistics with Python course. Feel free to take a look at Course Curriculum.
This tutorial has an educational and informational purpose and doesn’t constitute any type of forecasting, business, trading or investment advice. All content, including code and data, is presented for personal educational use exclusively and with no guarantee of exactness of completeness. Past performance doesn’t guarantee future results. Please read full Disclaimer.
An example of probability distributions is normal probability distribution which consists of all possible values that a continuous random variable can have and their associated probability of being observed. Its probability distribution function is bell-shaped, symmetric from its mean and mesokurtic. Standard normal probability distribution consists of normal probability distribution with mean zero and unit variance. Any normal probability distribution can be converted into a standard normal probability distribution through continuous random variable standardization.
1. Formula notation.
Where = normal probability density function,
= continuous random variable,
= normal probability distribution mean,
= standard normal probability distribution mean,
= normal probability distribution variance,
= standard normal probability distribution variance,
= normal and standard normal probability distributions skewness,
= normal and standard normal probability distributions excess kurtosis,
= continuous random variable standardization,
= continuous random variable mean,
= continuous random variable standard deviation.
2. Python code example.
2.1. Import Python packages [1].
import numpy as np
import pandas as pd
import sklearn.preprocessing as sl
import scipy.stats as st
import matplotlib.pyplot as plt2.2. Probability distributions data reading, standardized daily returns calculation and standardized daily returns descriptive statistics output.
- Data: S&P 500® index replicating ETF (ticker symbol: SPY) daily adjusted close prices (2007-2015).
- Data daily arithmetic returns and standardized daily arithmetic returns calculation.
spy = pd.read_csv('Data//Probability-Distributions-Data.txt', index_col='Date', parse_dates=True)rspy = spy.pct_change(1).dropna()
srspy = sl.scale(rspy)In:
print('== Standardized Daily Returns Descriptive Statistics ==')
print('Mean:', srspy.mean())
print('Standard Deviation:', srspy.std())
print('Skewness:', st.skew(srspy))
print('Excess Kurtosis:', st.kurtosis(srspy))Out:
== Standardized Daily Returns Descriptive Statistics ==
Mean: -6.27410804203179e-18
Standard Deviation: 1.0
Skewness: [0.21692697]
Excess Kurtosis: [13.61300109]2.3. Standardized daily returns density histogram and standard normal probability distribution curve overlay chart.
hbins = int(np.round((1 / np.histogram(srspy, density=True)[0].sum()) *
(len(np.histogram(srspy, density=True)[1]) - 1)))
plt.hist(srspy, bins=hbins, density=True, label='srspy')
plt.plot(sorted(srspy), st.norm.pdf(sorted(srspy)), label='n(m=0,sd=1)')
plt.title('SPY Standardized Daily Returns Histogram')
plt.ylabel('Density')
plt.xlabel('Bin Edges')
plt.legend(loc='upper right')
plt.show()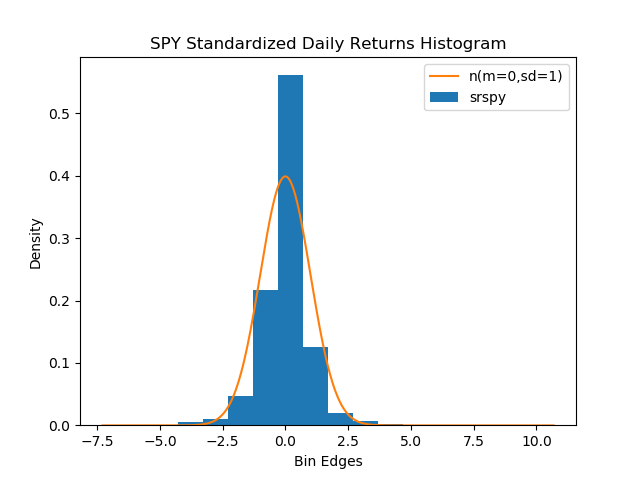
3. References.
[1] Travis E, Oliphant. “A guide to NumPy”. USA: Trelgol Publishing. 2006.
Stéfan van der Walt, S. Chris Colbert and Gaël Varoquaux. “The NumPy Array: A Structure for Efficient Numerical Computation”. Computing in Science & Engineering. 2011.
Wes McKinney. “Data Structures for Statistical Computing in Python.” Proceedings of the 9th Python in Science Conference. 2010.
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, Édouard Duchesnay. “Scikit-learn: Machine Learning in Python”. Journal of Machine Learning Research. 2011.
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, CJ Carey, İlhan Polat, Yu Feng, Eric W. Moore, Jake VanderPlas, Denis Laxalde, Josef Perktold, Robert Cimrman, Ian Henriksen, E.A. Quintero, Charles R Harris, Anne M. Archibald, Antônio H. Ribeiro, Fabian Pedregosa, Paul van Mulbregt, and SciPy 1.0 Contributors. “SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python”. Nature Methods. 2020.
John D. Hunter. “Matplotlib: A 2D Graphics Environment.” Computing in Science & Engineering. 2007.